
Editor's note: This article was originally published by Dan Coughlan on his Substack, in June 2026. It has been republished here as part of Airtree's Open Source VC library.
There’s a growing chorus emerging in pockets of the AI world with an almost heretical claim: LLMs are insufficient. Despite blowing through benchmarks no one thought possible this decade, and being responsible for the fastest-growing businesses in history in Anthropic and OpenAI, they alone will not take us to the promised land of AGI. They describe the world, but they do not understand it, or at least not the way we do.
The chorus contains some of the loudest voices in the AI discourse. Yann LeCun, Meta’s former Chief AI scientist, says LLMs are an architectural dead end on the path to general intelligence. Demis Hassabis, founder of DeepMind and Nobel Laureate, argues that getting to general intelligence will require systems capable of “actually understanding the physics of the world, the causality of the world”. He wants systems that can run simulations of reality forward to test hypotheses.
Although the voices may disagree on the specifics, what they call for is a “world model”. Something capable of understanding the world, simulating it, and making predictions based on those simulations. The bet is that this missing layer can’t be reached by scaling what we already have. It requires training on something other than text, an architecture that does more than predict the next word.
Text is not enough
As humans, our creation and command of language sets us apart from our fellow animals, making us more capable and our intelligence more generalisable. It has enabled us to explain our findings and pass knowledge across generations. It has also allowed us to coordinate groups by the thousands, beyond the family or the village. It allowed us to create narratives, nations, money, laws, and then build civilisations on top of them. The ability to efficiently encode the world in symbols paved the way for humans to compound our collective understanding of that world.
But language is not reality, just as the map isn’t the territory. Language is a compressed version of the world. This compression is the source of language’s power and the limit of its reach in the same breath. Compression is what made language portable, but it’s also what made language partial. When we speak about reality, we are always speaking about a thinned, simplified version of it. Oliver Cameron (Co-founder & CEO of Odyssey) asks the question: could you learn to swim purely by reading a book describing it?
Language is too abstract to convey the foundational understanding of the world. As Demis suggests, what is needed is an understanding of causality. The animal world is full of intelligence that operates without language on this basis: observation and action.
In the 1990s, biologists in the Japanese city of Sendai began noticing that the local carrion crows had figured out a trick. They would carry walnuts from nearby trees, drop them onto the pedestrian crossing at a busy intersection, and perch on the wires above to watch. When the lights turned green and traffic flowed across, the tyres of passing cars would crack the shells. When the lights turned red and the cars stopped, the crows would hop down onto the road, pick through the kernels, and fly off.
Our ape cousins have been observed opening locked doors, using vending machines, and driving golf carts. As Jim Fan from NVIDIA puts it, they have a robust mental picture of “what ifs”: how the physical world works and reacts to their intervention.
It’s telling that even for us humans, roughly a third of our cortex is devoted to vision, distributed across the occipital, temporal and parietal regions. Language sits in a much smaller area, mostly clustered around the left temple. Vision carries more raw information per second than any other sense. As Yann LeCun emphasises, a four-year-old has absorbed roughly fifty times as much sensory data through vision alone as the largest LLM has absorbed through text.
Humans and animals alike have the benefit of many years of the highest fidelity data collection available – living – before we’re expected to be useful, as well as “evolutionary priors” encoded into roughly 3GB of DNA. For a world model, we have to show them the richest, largest-volume representation of the world: video. Fortunately, this dataset has been growing rapidly, aided by smartphones and the proliferation of online video content, which has created trillions of observations of our world showcasing physics, dynamics, sound, and human behaviour in action.
What is a world model
What you train a model on, in this case video data, is only part of the equation. The harder part is what you train it to do. This brings us to one of the most contested questions in AI right now: what should a world model do? The term gets thrown around to describe many different types of models, aiming to do many different things. In order to distinguish them, I borrow a helpful taxonomy from Jeff Hawke, Co-founder and CTO of Odyssey:
- General purpose world models: “learn how the world evolves.”
Given the current state of the world and an action, they predict the next state. They model dynamics: how things change over time and in response to intervention. It is a model that understands the world well enough to predict what happens next.
- Spatial intelligence models: “learn how the world appears.”
They reconstruct the structure of a scene, its geometry and layout, but do not model how it changes when something acts on it. Fei-Fei Li’s World Labs is the clearest example. A spatial intelligence model can tell you what a room looks like in three dimensions. It cannot tell you what happens if you tip the table over.
- Behaviour models: “learn how to act within a world.”
A model learns which action to take in a given state. This is also referred to as ‘policy learning.’ Robot foundation models like those from Physical Intelligence fit in this camp. Many behaviour models are paired with attempts to model how the world evolves – NVIDIA’s DreamZero is an example in the robotics space and vision-action-language (VLA) models are another attempt to do so (although we would point to the limitations in language’s ability to capture causality). Wayve, where Jeff helped pioneer research for five years, is a great example of the power of a behaviour model (the policy that dictates the driving of the car) with a narrow, domain-specific world model.
- Proxy world models: “learn an abstraction of the world.”
Models that learn an abstraction of the world as a byproduct, rather than by explicitly predicting how it evolves under action. Some have argued that language models are world models because they can form internal representations of states. However, as we discussed above, this is a compressed and indirect model of the world. They learn a proxy for underlying phenomena through language.
The defining characteristic of predicting state based on action is a key distinction that also helps us draw a line between a world model and a video generation model. Take Sora, OpenAI’s now-shelved video model. It used a bidirectional attention mechanism, meaning all frames could see all other frames simultaneously, allowing for much better coherence (i.e. at each step the model knows what all the frames before and after it look like, which helps avoid things like disappearing bodies or oversaturation of colours as the video rolls). But the drawback of bidirectional attention is that the outcome is entirely predetermined. You can’t inject an action mid-stream and interact with the world being portrayed.
A world model, on the other hand, generates video outputs that respond to action in real time. The mechanism for doing this is called autoregressive generation, which means the model produces one piece of the output at a time, with each new piece conditioned only on what has already been produced. LLMs work this way too. GPT generates one token at a time, conditioned on the tokens that came before it. The future, in the model’s view, is open until it generates it. Rather than a pre-determined “movie”, the result is a simulation of an environment that responds to intervention.
It is this ability to simulate that gives rise to a fundamentally different kind of intelligence, a truer sense of “understanding”, and a step closer to resolving Demis’ missing puzzle piece.
The dominant view in cognitive science for the last several decades is that the brain is fundamentally a prediction engine. Kenneth Craik’s framing from 1943 (The Nature of Explanation) was that humans carry “small-scale models” of reality in their heads to anticipate events. Not a passive recogniser of the world, but a system that is constantly anticipating what is about to happen, conditioned on what the body is about to do, and updating against the difference between expectation and outcome. We are the ape with our robust “what ifs”. By taking actions during training and seeing what changes, a world model learns more than the statistical pattern of what tends to happen. It learns something closer to what makes things happen. It learns causality.
Judea Pearl, the computer scientist who has done the most to formalise causality in machine learning, talks about three rungs of the causal ladder. Rung one is correlation: things that tend to happen together. Rung two is intervention: what happens when you do something. Rung three is counterfactual: what would have happened if you had done something else instead. Large language models are extraordinarily good rung-one machines. They have absorbed a vast amount of statistical structure about how humans describe the world. They are not architected to climb cleanly to rungs two or three. A world model is an attempt to build a system that natively operates on rungs two and three. It does not just record that things tend to co-occur. It can be intervened upon (rung two: do this, see what happens) and run counterfactually (rung three: what would have happened if I had done something else).
History of world models
A recent piece by Henry Yin and Naomi Xia at MoE Capital eloquently laid out the history of world models as two parallel areas of research that have recently converged: (1) learning to dream and (2) learning from watching.
- Learning to dream:
Rooted in the domain of reinforcement learning (RL), this approach to world models is based on the idea that a sufficiently capable network could learn to predict the consequences of its own actions, and that this internal simulation could substitute for a lot of real-world experimentation. Nearly 30 years later, in 2018, Ha and Schmidhuber’s paper “World Models” posed the question: Can agents learn inside of their own dreams? The answer was a vision encoder, a memory module, and a tiny controller (just 867 parameters) trained on a toy game environment that learned to act inside its own simulation.
NVIDIA’s Dreamer series of models is based on the same idea but extended to hundreds of control tasks. In 2022, they deployed their DayDreamer model on robots and quadrupled the rate of learning to walk from scratch in one hour of real-world interaction by simulating thousands of practice runs for every real-world deployment.
- Learning from watching:
The second thread emerged from of video generation, where researchers were exploring models that could learn behaviours and transferable physical representations of the world from video training data. Diffusion model breakthroughs then showed they could produce realistic video based on internet-scale training data. OpenAI’s 2022 VPT model learned to play Minecraft based on 70,000 hours of gameplay video. Models like Sora (OpenAI, 2024) and Veo (DeepMind, 2024) demonstrated remarkably coherent video generation that appeared to understand the laws of physics. The catch was that none of these systems were designed to roll the world forward causally. They were not able to generate video responding to specific actions.
The recent excitement around world models largely represents the convergence of these two threads. The RL camp brought action-conditioning and the concept of learning via simulation, while the video camp brought generalisation through realistic, scalable scene generation trained on massive amounts of data. What followed was a sequence of architectural breakthroughs that have laid the foundation for today’s world models.
In the last section we distinguished between bidirectional and autoregressive generation. There is a deeper layer to this and it has to do with an underlying architectural tradeoff:
- Diffusion Transformer (DiT). Developed by Peebles and Xie in 2022 and quickly became dominant for video generation. DiTs treat an entire video clip as a single block of tokens spanning height, width and time, and apply joint attention across the whole block. The result is photorealistic, temporally coherent video at scales the ST-Transformer family could not match. DiTs are by default bidirectional. They were originally designed for image generation, where there is no temporal direction and then extended to video generation where the bidirectional attention would help ensure self-consistency.
- Spatio-Temporal Transformer (ST-Transformer). Spatial attention within a frame, in which every position sees every other position. Temporal attention across frames, in which each frame can only attend to the ones before it. ST-transformers emerged from sequential video modelling, where next-frame prediction was typically the training task and autoregressive attention made sense. The tradeoff is worse fidelity, particularly for photorealistic generation, versus DiTs.
Up until 2025, the field faced a choice: use a DiT and get the best video quality available, with a predetermined output, or use an ST-Transformer and get autoregressive, action-conditioned generation, at the cost of fidelity and scale. Sora, Veo and Runway’s Gen-3 took the former approach and produced photorealistic, high fidelity, video outputs. Genie 1 took the latter and showed the power of autoregression for interactive simulation.
Then, in 2025, researchers from MIT and Adobe resolved this trade-off. The CausVid paper leveraged distillation, the concept of using one model to train another, to bring the quality of bidirectional DiTs to a model that produces sequential frames on-the-fly. They used a technique called distribution matching distillation, using a high-fidelity bidirectional model as a “teacher“ and then training a fast, causal, autoregressive “student” model to match the output distribution of a slow, bidirectional, high-quality teacher. The student inherits the teacher’s quality while being causal, interactive, and roughly an order of magnitude faster. This architecture, now known as autoregressive diffusion transformers (AR-DiT), has emerged as the dominant way of building world models.
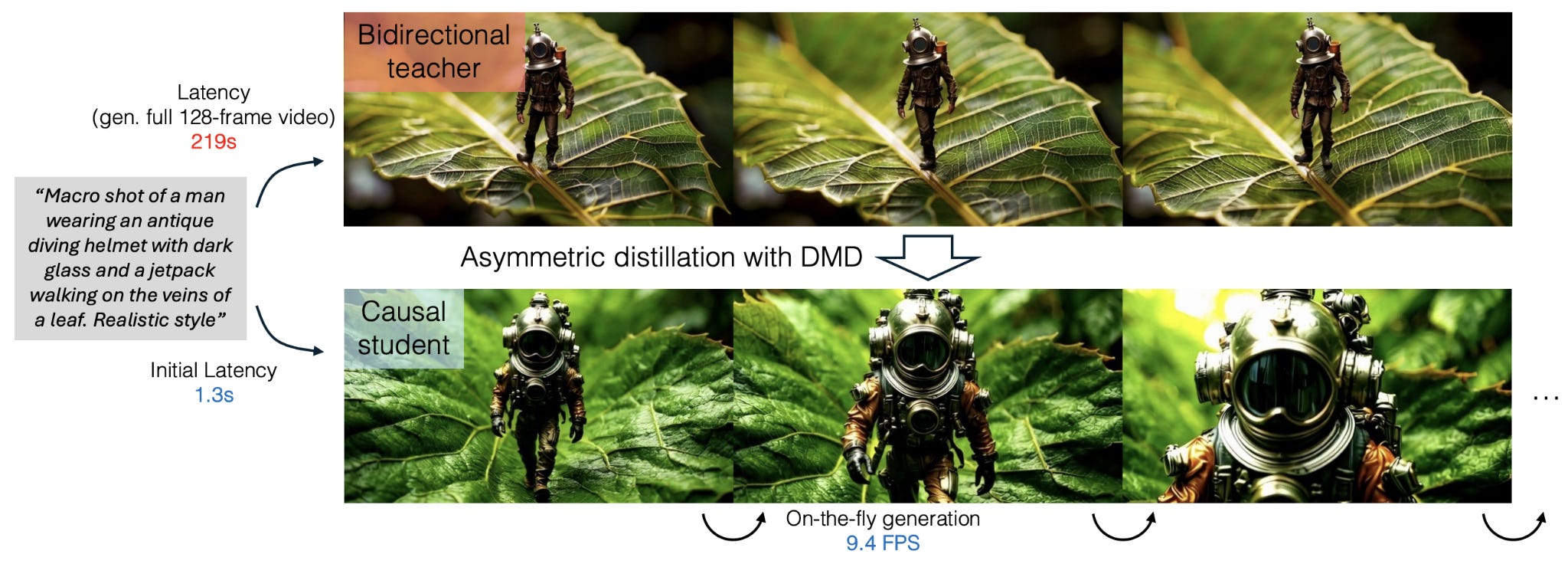
There were other gaps to be solved after the CausVid paper, most notably stability. Generating a world one frame at a time creates a problem in that each new frame is built on the frames the model has already produced. This means errors get fed forward and compound, so if you run the model long enough, the picture drifts (colours oversaturate, scenes melt, motion stalls). The root cause is a mismatch between how these models are trained and how they are used. In training, they were shown real past frames and asked to predict the next one. At inference time, there are no real past frames, only the model’s own imperfect output, and nothing in training taught it to cope with that. A line of work through 2025, beginning with Self Forcing (from the same group as CausVid) closed most of this gap by training the model the way it actually runs, i.e. letting it generate its own rollout during training and learn to recover from its own mistakes. This was then extended by a different group of researchers in Self-Forcing++ which enabled coherence over longer time horizons (up to ~4 minutes). It’s worth noting that the underlying tendency to drift has been managed rather than solved, and it remains one of the genuinely open research problems in the field.
World model use cases
What can you do with a runnable simulator of the world and where are we at today?
- Autonomous vehicles
Driving is where world-model techniques first came into contact with the real world, and Oliver and Jeff from Odyssey were right there on the frontline. Strictly, in the taxonomy from earlier, driving systems are behaviour models: world modelling bound to one agent and one task. But that narrowness is exactly why driving got there first. A self-driving system has to predict how a scene will evolve over the next few seconds, conditioned on its own planned trajectory, evaluate counterfactuals (”what happens if I brake instead of swerve”), and stay coherent over time, all under safety-critical constraints that did not allow the hard problems to be deferred. Wayve’s approach is the most philosophically aligned with what we call a world model, emphasising an end-to-end learning approach and the ability to generalise. It’s this philosophy that underpinned their ability to zero-shot over 500 cities (i.e. drive in them despite no prior training or testing on that specific city).
- Interactive media & gaming
A world model that generates a coherent, navigable environment in real time is, functionally, a game engine. For games, the bar for physics accuracy is lower than robotics and thanks to the ability to train on gameplay data, it’s an achievable level.
We see two paths for “world models” (in the broadest definition) to be used in gaming:
- Accelerating existing content pipelines with traditional 3D tools. E.g. using Spatial Intelligence models like World Labs to speed up the labour-intensive process of asset creation.
- Exploring entirely new game engine paradigms.
The former is a nearer-term commercial approach and rhymes with what we see across many different industries (use AI to automate the labour-intensive parts of existing workflows). That latter is harder to conceptualise, as paradigm shifts often are, but presents a truly disruptive bet with genuinely interactive, personalised worlds that generate on the fly in response to the player.
- Robotics
Robotics is the larger prize and the one most often overstated. It splits into two quite different uses.
a. Training
Robots need enormous amounts of data to generalise across tasks and environments, and collecting it in the real world is painfully slow and expensive. Simulation generates it at scale: spawn a million variations of a kitchen counter with different objects, lighting and physics, and have simulated robots practise in parallel. It also solves the issue of training for “out of distribution” events. For example, certain scenarios may be unsafe or impractical to train for in the real world (e.g. have a child or animals running around robots). Simulation lets you solve these edge cases.
Simulation infrastructure exists today, but there are still issues replicating the real world closely enough, referred to as the sim-to-real gap. Existing physics engines approximate real-world physics through hand-coded equations and heuristics. As a result, they handle rigid bodies well but struggle with soft materials, fluid dynamics, and deformable objects. If a world model has a better representation of real world physics from end-to-end learning instead of engineered physics approximations, it would make more suitable representations for robots to train in. This is a larger problem during the upfront training phase for robots; however, it’s also an ongoing use case as form factors change, component parts change and simulation is needed to keep the base policy models accurate.
b. Onboard intelligence infrastructure
The even bigger prize, albeit more speculative, is for world models to serve as intelligence substrate powering robots. In this future, a robot runs two coupled systems: a world model that predicts “if I take action X in state Y, the world will look like Z,” and a policy that uses those predictions to decide what to do. The world model enables the robot to simulate the consequences of an action, with some understanding of how the physical world will respond, before committing to it.
This is the closest thing in practice to the kind of intelligence Demis Hassabis described at the start of this piece: a system that runs a model of reality forward, tests what would happen, and acts on the result rather than on a memorised pattern.
- Simulation as an instrument
Even more speculative is the idea of using world models as a scientific instrument. The argument runs like this: a model that has internalised the dynamics of physical systems from enough observation is, by definition, a simulator you could run experiments inside, exploring counterfactuals at a speed and scale no physical laboratory can match. This is the version of the future Demis Hassabis envisions, in which world models as systems that can run simulations to test their own hypotheses, the way human scientists do.
That said, it’s worth noting key scientific breakthroughs like AlphaFold have been produced by specialised models rather than general-purpose simulators.
The field of play
Horizontal generative world models
These models predict the next state of the world, represented as pixels. In the case of Odyssey, this is also truly multimodal with interactive audio.
- NVIDIA: A heavyweight with strong historical simulation capabilities (Isaac Sim). NVIDIA have released important research in the field, particularly as it relates to robotics use cases. Its DreamDojo (February 2026) is an action-conditioned world model trained on roughly 44,000 hours of egocentric human video, built on the Cosmos foundation model line. They also recently announced DreamZero, a world-action model that jointly predicts future world states and the actions that produce them. Earlier this month, NVIDIA released Cosmos 3, which folds physical reasoning, world generation and action prediction into a single open model rather than the separate systems of earlier releases. So far, the strategy appears consistent with how NVIDIA has explored other areas of AI: drive research breakthroughs, then open source them and let others build on top to drive demand for chips.
- Google DeepMind: Genie 3’s release in August 2025 set a strong benchmark for world models. Google has strong resources and the benefit of owning YouTube, the main drawback is the competing priorities of a large company with many different AI bets to place. As we’ve seen in the LLM world, singularly focused teams can achieve a lot with comparatively fewer resources.
- Odyssey: The most concentrated expression of the generative approach. Pureplay frontier quality world model based on video generation in Odyssey 2-Max (April 2026), in addition to new releases around interactive audio generation (synchronised with video), and multi-agent environments. See the next section for more details on why we’re excited to be backing Odyssey.
- Runway: With its origins in bidirectional video generation models, Runway has more recently focused on world models. GWM-1 (December 2025), is a real-time pixel-prediction, released in worlds, robotics and avatar branches.
- Decart: The Oasis model, released in 2024, was one of the first clear proof points that a real-time, autoregressive, playable world model was possible. Decart now describes itself as a vertically integrated world-model lab. It has built its own optimisation and infrastructure stack, DOS, specifically to run real-time world models, with two model lines, Lucy for immersive media and Oasis for physical AI. Its latest release, Oasis 3 (June 2026), generates hours of photorealistic, interactive driving environments via API, pitched at autonomous-vehicle developers who need to simulate rare scenarios at scale.
Latent space model
While the models above focus on predicting pixels, there is a research camp that argues this is a mistake. The camp is led by Yann LeCun, who is pioneering this approach through AMI Labs and their JEPA (Joint Embedding Predictive Architecture) models. Their case is that most of what happens in the world is unpredictable at the level of individual pixels, so a model that tries to reconstruct the image spends its capacity on details that don’t matter and cannot be predicted anyway. The alternative is to predict in an “abstract representation”, learning what changes about the world rather than how it looks, and never rendering an image at all. The way I’ve heard this framed is that instead of predicting what the next state will look like, a latent model like JEPA predicts what the next state will mean.
In this context, an abstract representation is a compact summary that captures meaning rather than the actual pixel-by-pixel representation. If you ask a person to recall an image they saw briefly, they don’t remember every pixel, but they remember “a red apple on a wooden table by a window”. That sentence is an abstract representation. The main difference between this abstraction and the one produced by a JEPA model, is that instead of encoding it in natural language, the model encodes it as a list of numbers known as vectors. As an oversimplified example, a red apple might be represented as [0.934, 0.821, 0.902, -0.411, 0.808] where the slots represent [redness, roundness, food, size, natural]. A green apple might therefore be presented as [-0.703, 0.824, 0.902, -0.409, 0.808] – they only differ on the redness dimension, so the model is encoding that they almost mean the same thing. In reality, these models often have hundreds or thousands of “slots” and they rarely have a single clean slot per human-readable feature.
The other key difference between our natural language analogy and latent space models is that the vocabulary of vectors is learned rather than designed. When a person says “a red apple on a wooden table by a window,” each word has a meaning they have inherited from English. When the model produces its vector, there is no predetermined meaning for each number. The vocabulary emerged from training. Through the process of seeing millions of images and slowly adjusting its learnable numbers, the model arrives at a representation in which particular numbers correspond to particular features.
The payoff for working in this compressed space is efficiency. Because the model reasons over a compact representation rather than generating full images, it can plan far faster than a system that has to render every pixel. Meta’s V-JEPA 2 plans robot actions directly in representation space without ever rendering a pixel, and does so far faster than a comparable pixel-based system, 16 seconds to decide an action versus four minutes for NVIDIA’s Cosmos.
The drawbacks that critics of the latent space approach point to largely revolve around evaluation. It’s much harder for a person to intuitively make sense of a list of numbers representing unknown dimensions compared to reviewing the output of a video generation model. Evaluating these models usually means training a second, much smaller model called a “probe”. The probe is given the representation and asked to read off one specific property from it, say, what objects are in the scene, how far away they are, or whether two things are about to collide. If a simple probe can reliably recover the distance to an object, that information must already have been sitting in the representation. Researchers can also train a decoder, a network that turns the representation back into a viewable image, so you can actually see what the model is encoding.
To be clear, the latent camp would likely argue this is a feature, not a bug – you can’t “eyeball” the outputs because the model isn’t wasting capacity on human-legible detail. Nonetheless, evaluating and interpreting these models requires indirect, more effortful methods and a decoder can only show you a plausible reconstruction rather than the exact prediction.
Another interesting approach in the space is being pioneered by Chris Manning, one of the most credentialed Australians in AI, alongside Ian Goodfellow (inventor of generative adversarial networks, “GANs”) and Fan-Yun Sun, who are building Moonlake AI. They appear to be adopting a hybrid approach whereby they generate full, attractive game environments specifically to draw in human players, use those players to produce action-labelled data, then discard the pixels and model the world in an abstract, symbolic space.
3D Reconstruction + Dynamics
Earlier, we placed spatial intelligence in a different bucket to world models, because spatial intelligence models how the world appears, not how it changes when something acts on it. This distinction limits the use of these systems as standalone simulators for tasks like robotics training or gaming, where you need to know not just what a scene looks like but how it responds when the agent interacts with it.
The natural move for the spatial intelligence builders is to supplement their 3D reconstruction with hand-engineered dynamics. World Labs’ Marble generates photorealistic 3D environments and exports them in two forms at once: Gaussian splats for visual fidelity, and collider meshes that a physics engine can act on. These drop straight into simulators like NVIDIA’s Isaac Sim (as well as MuJoCo and RoboSuite), with the physics, contact resolution and dynamics handled by the sim itself. NVIDIA has published a workflow on this basis that compresses the setup of a robotics environment from weeks into hours, and World Labs describes the dual output as dissolving the boundary between rendering and simulation.
It’s a pragmatic approach that aims to reduce the engineering burden of existing simulation workflows, but it doesn’t address some of the limitations of those workflows. The ceiling of hand-coded physics remains: good with rigid bodies, weaker with soft materials, fluids and deformation, and ultimately constrained by what an engineer chose to model.
Odyssey: polytropos
What precedes this is a reflection on months of meandering research and conversations with people much closer to the frontier than we are. What follows is the result: a high-conviction investment in what we believe to be the emerging category leader and a team that is setting the pace for the rest of the field. That company is Odyssey, and we are pleased to be investing in their US$300M Series B alongside Natural Capital, GV, EQT, In-Q-Tel, NVIDIA, AMD, Point Nine, Axiom, Amazon and others.
A team with deep experience deploying interactive models to the real world
Odyssey was founded in late 2023 by Oliver Cameron and Jeff Hawke with the ambition of building a general-purpose world model. For Oliver and Jeff, Odyssey represents a continuation of a decades-long obsession with getting AI to interact with the real world. As we’ve noted, autonomous vehicles have been the most formative proving grounds for world models, and in particular, Wayve is credited for being the first demonstration of world models interacting with the real world. Jeff was a critical part of this journey, in 2019 he co-authored a paper, “Learning to drive in a day,” which demonstrated for the first time that you could use deep reinforcement learning to teach a car to follow a lane on real roads, from scratch, using only a single camera image as input. It was an early proof of concept for the end-to-end learning paradigm that Wayve, and now much of the AV industry, was built on. Oliver was early to the self-driving world, co-founding Voyage in 2017 and deploying a self-driving car on the road 7 months post-launch. They went on to build three generations of robotaxis before being acquired by Cruise (the formerly General Motors-backed AV company).
It’s not just Oliver and Jeff, either; they’ve assembled a world-class team replete with experience in the AV world, but also gaming and robotics expertise and researchers from frontier AI labs. This is a team that has seen their research make contact with the real world and knows what it takes to get to successful deployments. We think the strong mix of applied engineering experience matters more than citations in a space like this and it’s an incredible asset for Odyssey.
Rapid research velocity
Odyssey released its first model, Explorer, in November 2024. Explorer was focused on producing explicit 3D representations from seed images, comparable to World Labs’ Marble (released in November 2025). They started here for a specific reason – to test their hypothesis that models could learn geometric consistency implicitly from high-quality data sources with enough scale. For multi-modal world models, this means modelling transition dynamics from the largest source of data possible: learning from audio-visual observations via video.
Since that point, Odyssey have been pioneering interactive, AR-DiT models focused on learning to simulate the world. And this team moves fast. Up until today, they had only raised ~US$45M and have a team of ~50, much less than most of their peers on both fronts, yet they’ve been breaking ground on new research at a rate that has required me to update this article multiple times.
Odyssey 1 (May 2025): Their first real-time, playable world model with WASD navigation controls and coherence over several minutes.
Odyssey-1.5 (June 2025): Extended Odyssey-1 to a more diverse range of visual and action data.
Odyssey-2 (October 2025): 480p interactive simulations at 20 FPS, with open-ended event conditioning via text embeddings rather than only navigation keys.
Odyssey-2 Pro (December 2025): Early signs of scaling laws in world models. A significantly larger version of Odyssey-2 with the same architecture demonstrated better physics, dynamics and visuals. Resolution lifted from 480p to 720p, frame rate from 20 to 24 FPS.

Odyssey-2 Max (April 2026): Scaling laws pointing to not only better visual plausibility but also more stable physical dynamics. With ~3x the parameters and ~10x the training compute of Pro, Odyssey-2 Max saw physics performance on VBench 2 jumped from 49.67 to 58.52, exceeding NVIDIA’s Cosmos-Predict 2.5-14B on the same physics benchmarks. It also produced emergent physical behaviour that smaller models had not, including more coherent grasping, more plausible cloth and fluid interactions, and more stable long-horizon motion.


In the past month, they’ve continued to drop meaningful updates:
- PROWL (12 May): An RL method where an agent hunts for where the world model breaks, allowing the model to learn from its own failures. Pathway to continuous learning through interaction.
- Starchild-1 (17 May): the first ever world model that incorporates sound, meaning users can interact with and hear sounds generated in a real-time simulation.
- Agora-1 (18 May): a multi-agent world model. Up to four participants, human or AI, sharing and acting in the same simulated world in real-time, with consistent views from every viewpoint. A learned multiplayer game engine.
Bitter lesson-pilled
Rich Sutton, one of the forefathers of modern AI and an important steward of the reinforcement learning lineage for world models, published a famous 2019 essay titled The Bitter Lesson. The eponymous lesson, he states, is that “general methods that leverage computation are ultimately the most effective, and by a large margin.” Methods that continue to scale with increased computation, taking advantage of the falling cost of that computation over time, outperform human-crafted, task-specific systems.
This articulation has proved prescient. For many in the NLP community, the introduction of LLMs have been an example of the bitter lesson: for years, NLP researchers would hand-engineer part-of-speech taggers, named-entity recognisers, parse trees and grammar, only for LLMs to absorb all of it natively from internet-scale data and massive compute. In the world of self-driving, Wayve’s “end-to-end” learned approach is a similar story: teach a model to drive directly from vision and action rather than bolting together hand-coded rules and separate modules for things like LiDAR object detection. Tesla made the same move, cutting 300,000 lines of code worth of human-crafted rules in favour of an end-to-end neural network that leverages their huge base of vision data and massive computation.
Some look at the output of generative video models and dismiss them as toys, too incoherent and unstable to be useful. Others can see potential in interactive media, and perhaps gaming but struggled to imagine utility in robotics. We think we’re approaching a GPT-3 moment, and the future of world models is bitter-lesson-shaped. Systems that learn how the world works from an immense scale of real-world observation will, in time, outperform systems built on explicit physics engines and hand-authored 3D representations.
The bitter lesson tells us the direction but not the timeline, and the timeline is genuinely uncertain. We are not yet at the point of adding massive computation and data and expecting jumps in real world capability. There are real research breakthroughs still to be made particularly around stable physical dynamics. But the direction of travel favours the learned approach, and Odyssey’s, forged in the labs of Wayve, is well positioned.
Thank you to Jace Chua, Dong Gong, Antoine Nguyen, and the rest of the Airtree Journal Club for all the insightful conversations about world models.
Thank you to Bree & Jax from Airtree for helping me get this out the door.



AirTree Ventures Custody Pty Ltd holds AFSL No. 544106.
